导读: 随着大数据技术的发展,Spark成为当今大数据领域最受关注的计算引擎之一。在传统的生产环境中,Spark on YARN成为主流的任务执行方式,而随着容器化概念以及存算分离思想的普及,尤其是Spark3.1版本下该模式的正式可用(GA),Spark on K8s已成燎原之势。
今天的介绍会围绕下面两点展开:
Spark on K8s的基础概念和特性
Spark on K8s在阿里云EMR的优化和最佳实践
01
Spark on K8s的基础概念和特性
首先和大家分享下Spark on K8s的一些背景。
1. Spark的集群部署模式
Spark现如今支持4种部署模式:
Standalone :使用Spark的内置调度器,一般用于测试环境,因为没有充分利用到大数据的调度框架,无法充分利用集群资源。
Hadoop YARN :最常见的一种方式,源自Hadoop,拥有良好的社区生态。
Apache Mesos :与YARN类似,也是一个资源管理框架,现在已经逐渐退出历史舞台。
Kubernetes :即Spark on K8s,Spark3.1.1对这种部署模式正式提供可用支持,越来越多的用户也在积极做这方面的尝试。
使用Spark on K8s的 优势 如下:
提高资源利用率 :无需按照使用场景部署多个集群,所有Spark作业共享集群资源,能提高总体集群利用率,而且在云上使用时可以弹性容器实例,真正做到按量付费。
统一运维方式 :可以利用K8s的社区生态和工具,统一维护集群,减少集群切换带来的运维成本。
容器化 :通过容器镜像管理,提高Spark任务的可移植性,避免不同版本Spark带来版本冲突问题,支持多版本的A/B Test。
尤其需要关注的一点是,根据我们的测试,在相同的集群资源条件下,Spark on K8s和Spark on YARN的性能差距几乎可以忽略不计。再加上充分利用Spark on K8s的弹性资源,可以更好地加速Spark作业。
总结来看,Spark on K8s相较于Spark on YARN的模式来说,其实是利大于弊的。
2. Spark on K8s的部署架构
当前环境下,想要把Spark作业提交到K8s上,有两种方式:
使用原生的spark-submit
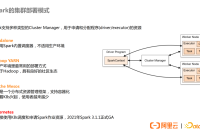
在这种方式下,K8s集群无需提前安装组件。像现在使用的YARN的提交方式一样,提交作业的Client端需要安装Spark的环境,并且配置kubectl,就是连接K8s集群的一个工具,然后在提交命令中标注K8s集群地址以及使用的Spark镜像地址即可。
上图详细的展示了使用原生的spark-submit提交任务到K8s的任务运行流程。用户在Client端执行spark-submit命令后会在本地启动一个进程,该进程会连接K8s的api server请求创建一个Driver Pod。Driver Pod在启动进程中会启动Spark Context,并负责申请Executor Pod。任务执行完毕后,Driver Pod会负责清理Executor Pod。但Driver Pod结束后会保留,用于日志或状态的查看,需要手动清理。
优点
这种提交方式符合用户的使用习惯,减少用户学习成本,与现有的大数据平台集成性更好。因为是Client模式提交,支持本地依赖,支持Spark-shell的交互式作业模式。
使用Spark-on-K8s-operator
Spark-on-K8s-operator是Google开源的一个组件,需要提前在K8s集群中部署一个常驻pod,以提供相关服务。与第一种方式不同的是,使用这种方式不再是以命令行的方式提交,而是使用kubectl提交一种yaml文件来提交作业。本质上来说,这种工具具体实现还是使用的spark-submit的方式,只是相当于命令行中的信息换了一种格式以文件的形式提交。但是Spark-on-K8s-operator在第一种方式的基础上,做了一些辅助工具,包括定时调度、监控、作业管理等。
从流程上来说,用户提交了一个yaml文件,在K8s集群上常驻的Spark-on-K8s-operator就监听到了这个事件,通过解析文件转化成执行spark-submit命令启动一个Spark任务。
除了提交方式的不同,我们刚刚也提到这个工具提供了一些辅助的功能。Spark-on-K8s-operator通过K8s的Mutating Admission Webhook机制,拦截了K8s的Api请求,在启动Driver和Executor Pod资源时,可以对其进行一些自定义配置处理。另一方面,工具可以监听Driver和Executor Pod的事件,从而跟踪和管理任务的执行进度。
优点:
工具的存在支持作业的管理,包括记录、重试、定时执行等。提供作业监控指标,也可以对接Prometheus方便统一监控。支持自动清理作业资源,也可以自动配置Spark UI的service/ingress。
3. Spark on K8s的社区进展
Spark2.3之前,有人尝试过通过在K8s上部署YARN的方式来支持Spark on K8s,但是本质上Spark还是跑在YARN的资源管控下,所以并不能称之为完整意义上的Spark on K8s。
Spark2.3,社区首次发布支持了原生的Spark on K8s,全是第一次官方支持这样的部署方式。
Spark2.4做了少量的特性优化,真正完善了这个功能是在Spark3版本,尤其是Spark3.1正式可用(GA)。当前Spark on K8s方向热度很高,所以如果感兴趣的同学建议直接升级到Spark3.1来尝试这个部署方式。
4. Spark on K8s的重点特性
优化Spark Pod配置属性
K8s的Pod定义通常采用Yaml的描述处理,早期的Driver和Executor Pod定义只能通过Spark Conf进行配置,灵活性很差,毕竟不是所有的配置都能通过Spark Conf处理。Spark3.0开始,支持使用模板文件。用户可以建立模板文件,定义Pod的属性,然后通过spark的配置传入,相较于单条配置更加便利,灵活性增强了很多。
动态资源分配(Dynamic Allocation)
Spark2版本时,动态资源分配只能使用External Shuffle Service(ESS)的方式,这种方式下,executor在执行时产生的shuffle数据全部交由ESS服务接管,executor执行完毕随时回收。但是这种方式一般由YARN的Node Manager启动管理,很难在K8s上部署。
Spark3版本中支持了Shuffle Tracking的特性,就是可以在没有ESS的情况下,利用自身对executor的管理,做到动态资源配置的效果。但是这种方式的缺点就是,在shuffle read阶段executor不能动态回收,仍需要保留以供reducer读取shuffle数据,然后需要等到driver端gc之后才会标记这个executor可以释放,资源释放效率低。
节点优雅下线(node decommissioning)
在K8s的环境中,节点的缩容,抢占式实例回收这些场景还是比较常见的,尤其是在一些场景下,将部分Spark的任务优先级调低以满足其他高优先级的任务的使用。这种场景下,executor直接退出可能会存在stage重算等情况,延长了Spark的执行时间。Spark3.1提供了“优雅下线”特性,支持Executor Pod在“被迫”下线前,可以通知Driver不再分配新的Task,并将缓存的数据或者shuffle的文件迁移到其他的Executor Pod中,从而保证对应Spark任务的效率,避免重算。
当前这个功能还属于实验性质,也就是默认不开启。
PersistentVolumeClaim复用
PersisentVolumnClaim(简称pvc),是K8s的存储声明,每个Pod都可以显式地申请挂载。Spark3.1支持动态创建pvc,意味着不需要提前声明申请,可以随着执行动态的申请挂载资源。但是这个时候pvc的生命周期伴随着Executor,如果出现上述的抢占式被迫关闭的情况,同样会出现保存在pvc上面的数据丢失重算的问题。所以在Spark3.2中,支持了pvc重新利用,它的生命周期伴随Driver,避免了重新申请和计算,保障整体的效率。
--
02
Spark on K8s在阿里云EMR的优化和最佳实践
接下来和大家分享下阿里云EMR对于Spark on K8s的优化和最佳实践。
1. Spark on ACK简介
ACK :阿里云容器服务Kubernetes版,简称ACK。
EMR :阿里云开源大数据平台E-MapReduce,简称EMR。
在阿里云公共云上,我们有一款EMR on ACK的产品,其中包含了Spark类型的集群,后面简称Spark on ACK。Spark on ACK这个产品是一套半托管的大数据平台,用户首先需要有一个自己的ACK集群,也就是k8s集群,然后我们会在这个集群内创建一个用于Spark作业的namespace,并安装一些固定组件pod比如spark-operator、historyserver之类,后续的Spark作业pod也会在这个namespace下运行,这些Spark作业pod可以利用用户自己的ACK节点机器来跑,也可以利用我们的弹性实例ECI来跑,来实现按量付费。这个所谓弹性实例ECI是什么,接下来我们具体介绍一下。
2. 云上弹性优势
Spark在云上最大的优势就是更好的弹性,在阿里云的ACK的环境中,提供了一个弹性容器实例ECI的产品,有了ECI意味着,我们申请pod时不再是占用自己的机器节点的资源了,而是完全利用云上资源来创建pod,而且可以做到快速拉起,秒级付费。利用ECI来跑spark作业我认为是非常划算的,因为通常大家用spark作业跑批处理任务,凌晨高峰,白天可能只有少量查询,这种峰谷明显的特点搭配快速弹性和按量付费是很适合的,外加ECI可以使用spot抢占式实例,有1个小时的保护期,并结合Spark的Node decommissioning特性,可以节省很多成本。
3. RSS优化Shuffle和动态资源
Spark Shuffle对本地存储依赖较大,但是云上环境下,存储分离的机器很难保障自带本地磁盘,使用云盘大小也无法预估,性价比不高。另一方面,Spark原生的无ESS的动态资源配置,executor的释放资源效率较低,可能因为无法回收造成资源浪费。
Spark Shuffle本身也有很多缺点 。Mapper的输出量增大,导致spill到本地磁盘,引发额外的IO;Reducer并发拉取Mapper端的数据,导致大量随机读的产生,降低效率;在shuffle过程中,产生numMapper * numReducer个网络连接,消耗过多CPU资源,带来性能和稳定性问题;Shuffle数据单副本导致数据丢失时,需要重新计算,浪费资源。
阿里云提供了独立部署的RSS,目前已经在github上开源,可以直接对接ACK,用户无需关注Shuffle数据是否有本地磁盘支持。原先的spark shuffle数据保存在executor本地磁盘,使用RSS后,shuffle的数据就交给RSS来管理了。其实采用push based的外部shuffle service业界已经是一种共识了,很多公司都在做这方面的优化。优点有很多,Executor执行完毕即可回收,节约资源;RSS还将传统的大量随机读优化成了追加写,顺序读,进一步弥补了Spark Shuffle的效率问题;RSS服务支持HA部署,多副本模式,降低重复计算的可能性,进一步保障Spark任务的效率。
4. 增强K8s作业级别调度
K8s默认的调度器调度粒度是Pod,但是传统的Spark任务调度默认粒度是application。一个Application的启动,会伴随启动多个Pod执行支持。所以,突然提交大量Spark任务时,可能出现大量Driver Pod启动,单都在等待Executor Pod启动,从而导致整个集群死锁。另一方面,K8s的多租户场景支持不佳,也不支持租户之间的弹性调度,以及动态配额等。相比于YARN的调度策略,K8s的调度策略单一,为默认优先级+FIFO的方式,无法做到公平调度。
阿里云ACK在这个方面做了增强:
调度时优先判断资源是否满足,解决上述可能出现的死锁问题。
基于NameSpace实现多租户树状队列,队列可以设置资源上下限,支持队列间抢占资源。
实现了以App粒度调度Spark作业的优先级队列,支持队列间的公平。调度,并基于Spark-on-K8s-operator的扩展,提交作业会自动进入队列。
5. 云上数据湖存储与加速
在K8s环境下,相比于传统的Hadoop集群,使用数据湖存储OSS更贴合存算分离的架构。Spark on ACK内置Jindo SDK,无缝对接OSS。
Fluid可支撑Spark on K8s部署模式下的缓存加速,在TPC-DS场景下,可以提升运行速度30%左右。
6. 使用DLF构建云上数据湖
在K8s上想要使用Hadoop 生态圈的组件,还需要额外部署。但是Spark on ACK无缝对接阿里云DLF(Data Lake Formation),DLF提供了统一的元数据服务,支持权限控制和审计,另外提供数据入湖的功能,支持Spark SQL的交互式分析,以及数据湖管理功能,支持进行存储分析和成本优化。
7. 易用性提升
Spark on ACK提供了一个CLI工具,可以直接以spark-submit语法来提交spark作业,同时也会记录到spark-operator里面来管理。之前我们提到了2种提交作业方式的优劣,spark-operator具备比较好的作业管理能力,但是提交作业不兼容老的命令语法,也无法跑交互式shell,从老集群迁移的用户改动比较麻烦,因此利用我们这种工具,可以同时享受2种提交方式的优点,对用户的易用性来说是个比较大的提升。
在日志收集这一点,Spark on ACK提供日志收集方案,并通过HistoryServer让用户可以像Spark on YARN一样在界面上查看。
今天的分享就到这里,谢谢大家。
分享嘉宾:范佚伦 阿里云 技术专家
编辑整理:李铭 多点dmall
出品平台:DataFunTalk
01/ 分享嘉宾
范佚伦| 阿里云 开源大数据部技术专家
负责阿里云EMR Spark on ACK产品功能研发。
02/ 关于我们
DataFun: 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100+线下和100+线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章800+,百万+阅读,15万+精准粉丝。



